TAG:VLA模型

时隔4年小米新款人形机器人亮相:可与人互动,还能“比心”、递纸袋
小米在投资者日时隔4年首次公开展示新款人形机器人,延续CyberOne外观并升级“灵巧手”,现场可完成递纸袋、比心等互动动作。结合其已在汽车工厂实习、依托触觉抓取与VLA模型实现打螺丝等能力,文章揭示了小米机器人从展示走向产业落地的最新进展。

小米新款人形机器人首次亮相:可与人互动,还能“比心”、递纸袋
小米在投资者日首次亮相新款人形机器人,现场完成“比心”、递纸袋等互动动作,重点升级“灵巧手”能力。结合此前已在汽车工厂进行上件、搬运等“实习”进展,小米透露其机器人依托触觉抓取与VLA模型技术,正加速迈向工业场景应用。

π0.7模型如何实现多任务统一学习,推动机器人真正具备“举一反三”能力
本文介绍了新一代机器人通用基础模型π0.7,探讨了其如何通过多模态上下文提示机制解决机器人“通用不等于好用”的痛点。该模型融合了Gemma 3的语义理解与流匹配Transformer的动作生成能力,不仅能理解复杂指令,还能根据视觉子目标与元数据实现跨平台适配与技能组合。π0.7在零样本任务和高灵巧操作上展现出的泛化潜力,标志着机器人从“照葫芦画瓢”向真正智能化的跨越。
超越VLA与世界模型:解析GEN-1、Being-H0.7与π0.7的架构演进与共性路径
本文深入解析了2026年涌现的具身原生模型新浪潮,重点探讨了GEN-1、Being-H0.7、π0.7及GR00T N1.7等前沿架构的进化。文章指出,具身智能正摆脱传统VLA与世界模型的局限,通过UMI设备、人类第一视角视频等原生数据实现规模化增长。通过对比隐式空间对齐与显式多模态调节等不同路径,揭示了行业在异构数据处理与物理世界理解上的突破,标志着具身智能正式进入原生时代。

阿里巴巴ATH开放式世界模型Happy Oyster开启体验 它石智航完成超4.5亿美金Pre-A轮融资
本期未来商业早参聚焦AI与消费新动态:阿里巴巴ATH开放式世界模型Happy Oyster启动早期体验,展现实时交互式生成新方向;它石智航完成超4.5亿美元Pre-A轮融资,具身智能赛道加速迈向量产落地;逐际动力开源VLA工程底座,推动研发标准化;大众点评“必玩榜”扩围,折射本地体验消费升级。
星动纪元拿下具身奥林匹克三项全球第一 成绩超越PI
在真机具身智能顶级赛事Benjie's Humanoid Olympic Games中,星动纪元凭自研VLA具身模型在剥橘子、开锁、翻袜子三项任务全面超越Physical Intelligence(PI),斩获三项全球第一并刷新纪录。文章解析赛事严苛规则、关键指标与星动纪元在小样本学习、视觉注意力与高频推理规划等技术上的突破。

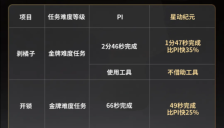
RL Token攻克VLA精度难题 在线强化学习助机器人精准操控
RL Token提出一种创新的在线强化学习框架,通过轻量级接口让预训练VLA模型在真实机器人上实现高精度操作的快速优化。该方法在保持泛化能力的同时,解决了传统方法在‘最后一厘米’精度任务中的效率与稳定性难题,为机器人灵巧操控提供了高效、可落地的技术路径。

UNC团队攻克VLA模型痛点 新方案提升任务成功率17%
北卡罗来纳大学教堂山分校团队揭示VLA模型在真实场景中因视觉主导语言而产生的指令偏离问题,提出无需修改架构的CAG优化方案,通过双分支对比引导语言决策,使任务成功率平均提升17.2%,反事实失效显著减少,为具身智能落地提供关键突破。
DreamZero开创具身智能新范式 语言理解迈向世界建模
本文探讨了具身智能领域中VLA模型面临的泛化能力不足和物理建模困难等问题,并介绍了英伟达推出的DreamZero,一种基于预训练视频扩散模型的新一代世界动作模型(WAM),通过整合视频与机器人动作,实现了跨任务、跨环境的零样本泛化和实时控制。

智元机器人ACoT-VLA框架获CVPR 2026收录 实现机器人动作空间自主决策
本文介绍了智元机器人联合北航团队提出的ACoT-VLA框架,该框架直接在动作空间进行思考决策,成功解决机器人执行动作中的语义与运动鸿沟问题,并在LIBERO、LIBEROPlus和VLABench三大基准测试中取得优异成绩。文章也探讨了其技术原理和创新点。

智元ACoT-VLA入选CVPR 2026 开源助力AGIBOT挑战赛
智元机器人联合北京航空航天大学推出的ACoT-VLA架构入选CVPR 2026,开创了在动作空间进行推理的思维链范式。该模型通过显式与隐式推理模块的结合,显著提升了机器人在复杂环境下的操控性能,并作为AGIBOT WORLD CHALLENGE的基线模型开源,助力全球开发者推动具身智能技术的发展。

PI VLA模型解读:多尺度具身记忆终结机器人金鱼脑
本文解读了Physical Intelligence团队提出的多尺度具身记忆(MEM)技术,该技术为VLA模型赋予了长达15分钟的连贯记忆能力,使机器人能够完成复杂的长时程任务。文章深入分析了机器人记忆实现的技术困境,包括存储与延迟的矛盾、长短时记忆的差异等问题,并展示了MEM如何突破这些瓶颈,推动具身智能进入全任务统筹的新阶段。

KAIST与UC Berkeley团队为VLA模型赋予记忆 实测成功率提升一倍
KAIST和UC Berkeley团队提出的HAMLET框架为视觉-语言-动作模型添加了历史记忆能力,解决了机器人在长时任务中因缺乏上下文而失败的问题。该轻量级插件通过时刻令牌和记忆模块整合关键历史信息,无需从头训练大模型,即在真实场景任务中将成功率提升高达47.2%,同时保持高效推理速度。
国产开源双臂机器人LingBot-VLA问世,2万小时实拍数据开启机器人GPT时刻
LingBot-VLA是一款国产开源双臂机器人视觉-语言-动作基础模型,通过整合9个主流平台约2万小时的真实世界操作数据进行预训练,显著提升了模型泛化能力和训练效率。该模型采用先进的视觉-语言骨干网络与扩散式动作头架构,在RoboTwin 2.0基准测试中表现出优越性能,并验证了数据规模与任务成功率之间的缩放法则。
Helix 02:移动与操作融合,实现人形机器人全身控制的VLA模型
本文介绍了Figure公司发布的Helix 02模型,该模型通过三层系统架构(System 0/1/2)实现了人形机器人移动与操作的无缝融合。文章详细阐述了其如何解决传统方案中动作僵化、切换迟缓的问题,通过统一的视觉语言模型(VLA)实现从场景理解到全身关节控制的实时、自主协同,提升了机器人在动态环境中的鲁棒性和自然运动能力。