

TAG:量化压缩
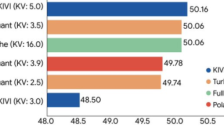
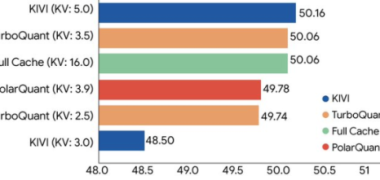
谷歌 TurboQuant 发布:LLM 键值缓存压缩六倍速度提升八倍 零精度损失无需训练
谷歌研究团队发布全新向量量化算法 TurboQuant,通过 PolarQuant 与 QJL 技术实现 LLM 键值缓存内存压缩6倍、推理速度提升8倍,零精度损失且无需训练。该技术可显著降低 AI 推理成本,推动长上下文应用落地,适用于广泛场景。


广州加速智能硬件研发 重点布局智能网联汽车与无人系统
2026-03-26
0 浏览
傅盛:模型竞争短期难分胜负 机器人业务两年内盈利
2026-03-26
0 浏览
广州加速具身智能机器人商业化 覆盖工业医疗家庭服务
2026-03-26
0 浏览
巴克莱解析特斯拉Terafab:1太瓦算力目标的技术挑战
2026-03-26
0 浏览
中科院启动下一代开源芯片与系统研发
2026-03-26
0 浏览
WPS AI热销助推金山办公业绩 海外收入大增54% 月活用户超8000万
2026-03-26
0 浏览
年产2500万条数据 这家公司打造人形机器人数据油田
2026-03-26
0 浏览
企业AI落地无忧 合规省钱API枢纽一键搞定
2026-03-26
0 浏览
月之暗面或启动港上市计划拟募资布局大模型高地
2026-03-26
0 浏览


