TAG:开源AI

商汤发布原生理解生成统一模型 SenseNova U1,告别插件式 AI
商汤正式发布并开源原生理解生成统一模型 SenseNova U1,基于 NEO-unify 架构打破传统多模态“插件式拼接”方案,实现语言与视觉在单一框架下统一理解、推理与生成,推动国产AI向更高效、更自然的结构化演进。

蚂蚁灵波开源世界模型LingBot-World-Fast,实现实时交互体验
蚂蚁灵光App上线“体验世界模型”,用户仅需上传一张图片即可在手机端生成60秒3D世界并以第一人称实时漫游。其核心为开源LingBot-World-Fast,480P下达16fps、交互延迟低于1秒,并通过后训练优化提升实时生成效率与时序一致性,支持本地部署与二次开发,面向具身智能、游戏与内容创作。

腾讯发布并开源全新AI大模型混元Hy3 Preview
腾讯于4月23日发布并开源全新大模型混元Hy3 preview,作为混元重建后训练的首个模型,也是当前系列最智能版本。该混合专家模型具备2950亿参数、256K超长上下文,强化复杂推理、指令遵循、代码处理与智能体能力,并已在腾讯云、元宝、QQ等多平台首发,后续将扩展至更多产品以提升智能服务体验。
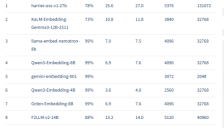
微软必应团队开源27B嵌入模型Harrier,多语言基准测试登顶
微软必应团队近日正式开源了旗舰级27B嵌入模型Harrier及其小参数版本。该模型在多语言MTEB v2基准测试中表现卓越,超越OpenAI、亚马逊及Google Gemini等领先专有模型,登顶榜首。Harrier支持超过100种语言,拥有32,000个词元的超长上下文窗口,并结合真实数据与GPT-5合成数据进行训练,具备强大的复杂语境和长文本处理能力。此次开源不仅为开发者提供了高性能的RAG系统和AI代理工具,更标志着开源AI在语义表示能力上取得重大突破,将加速多语言AI代理的全球落地。

月之暗面杨植麟:未来研究员将拥有海量Token,AI研发迈入AI主导时代
月之暗面创始人杨植麟在中关村论坛上分享AI研发未来趋势,提出大模型发展核心判断及Kimi最新技术路线。他强调Token效率、长上下文和Agent集群是规模化策略关键,并预测未来AI将主导研究工作,每个研究员将配备海量Token。文章还介绍了Kimi开源生态及大模型训练三阶段演进。

英伟达推出Nemotron 3系列开源模型 推理效率提升5倍
英伟达在2026 GTC大会上发布Nemotron 3系列开源模型,凭借Blackwell架构优化,推理效率提升5倍。新模型涵盖多模态交互、物理AI、机器人及医疗科研领域,支持从云端到边缘的快速部署,助力智能体与具身智能发展。

网易开源LobsterAI升级0.2.2版 支持企业微信和QQ
网易开源AI智能体平台LobsterAI发布0.2.2版本,新增企业微信和QQ机器人支持,实现国内主流IM工具全覆盖。该版本强化了移动端交付能力,支持远程驱动AI执行数据分析、PPT生成等任务,推动国产AI生态发展。

小米发布首代机器人VLA大模型并开源
小米宣布开源其首代机器人VLA大模型Xiaomi-Robotics-0,这是一个拥有47亿参数、结合视觉语言理解与高性能实时执行能力的开源模型。它采用MoT混合架构和异步推理模式,有效解决了机器人动作延迟和断层问题,在仿真测试和真实任务中均取得领先性能,实现了动作连贯、反应灵敏的物理智能。
警惕开源AI脱离监管风险:研究指出可能成为黑客攻击温床
SentinelOne与Censys的研究显示,脱离主流平台监管的开源大语言模型在私有环境中运行时,面临严重安全风险。研究发现数千个未受保护的AI实例,黑客可劫持模型生成垃圾信息、钓鱼邮件,甚至修改核心指令以支持有害活动,传统防护手段难以应对。

Clawd改名OpenClaw GitHub星标突破10万引发热议
开源AI助手项目OpenClaw经历多次更名后进入稳定阶段,GitHub星标数突破10万,网站访问量一周内超200万。该项目支持本地运行,通过常用聊天应用调用,实现邮件管理、日历处理等实用功能,强调数据隐私和社区驱动。
腾讯混元图像3.0开源,800亿参数引领AI创作新纪元
腾讯混元团队正式开源全球最强开源图生图模型——混元图像3.0,拥有800亿参数,采用混合专家架构,在LMArena榜单中位列第一梯队。模型通过‘先思考,后编辑’的核心技术,深度融合文本与视觉理解,支持增删改、风格变换、老照片修复等多种编辑功能,适用于从普通用户到专业设计师的广泛场景。
Hugging Face婉拒英伟达5亿美元投资背后
Hugging Face作为全球最大的开源AI模型平台,拒绝了英伟达5亿美元的投资邀约,以维护其在AI芯片市场中的中立地位。此举旨在避免过度依赖单一巨头,确保开源生态的公平与开放,展现了在资本浪潮下对技术纯粹性的坚守。
谷歌前CEO敦促欧洲投资开源AI 减少对外依赖
谷歌前CEO埃里克·施密特在达沃斯论坛上呼吁欧洲加大开源AI投资,避免对中国AI模型产生依赖。他指出美国偏向闭源模式,而中国在开源模型方面领先。欧洲需投资本土开源AI实验室并解决能源价格问题,以在全球AI竞赛中保持竞争力。

英伟达开源自动驾驶模型 推动物理AI发展
英伟达在CES 2026上宣布开源自动驾驶模型Alpamayo,标志着物理AI新时代的到来。该模型是全球首个能思考推理的开源AI系统,专为自动驾驶设计,并配套提供仿真工具AlpaSim和开放数据集。尽管在L2级市场面临竞争,英伟达通过与奔驰合作及开源策略,旨在推动自动驾驶技术普及并重夺行业话语权。

英伟达CEO称开源数据是未来AI信任基石
英伟达CEO黄仁勋在CES 2026上盛赞DeepSeek-R1开源模型的领先地位,并指出开源模型已反超闭源模型约六个月。他强调开源数据是构建AI信任的基石,并宣布英伟达将开源训练数据。同时,英伟达发布了涵盖语言、机器人、自动驾驶及医疗四大领域的全新模型与数据集,定义了多模态融合、跨环境部署和普及化加速的未来AI范式。