TAG:开源模型
DeepSeek V4中文大模型评测:再创国内第一佳绩
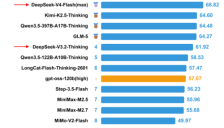
SuperCLUE最新评测显示,DeepSeek-V4-Pro以70.98分重回国内中文大模型第一,Flash版以68.82分位列第二。文章从六大能力维度解析其优势,并对比Pro与Flash在性能、成本和适用场景上的差异,同时指出其在代码与复杂指令上的提升空间,为企业与个人选型提供参考。

DeepSeek-V4预览版正式发布:1M超长上下文能力面向全员普惠
DeepSeek正式发布并开源DeepSeek-V4预览版,标志着1M超长上下文进入普惠时代。该系列分为Pro与Flash双版本,通过创新的DSA机制大幅降低长文本处理成本。模型在Agent协作、代码生成及逻辑推理性能上表现卓越,支持动态调节思考强度,不仅在性能上直逼顶级闭源模型,更通过技术突破加速了AGI的普及进程。
腾讯发布最新开源语言模型 Hy3 Preview,聚焦智能时代应用趋势
腾讯正式发布混元系列最新开源模型 Hy3 Preview,总参数量达295亿并支持256K超长上下文。该模型在复杂推理、指令遵循和代码处理等核心能力上显著提升,已广泛应用于元宝、QQ、腾讯文档等产品。此外,腾讯云同步推出了极具竞争力的API价格体系和定制化套餐,旨在通过高性能、高性价比的AI方案,助力开发者和企业在多样化场景下实现智能化升级。

阿里通义千问正式开源Qwen3.6-27B,编程能力实现“以小博大”表现
阿里云正式开源270亿参数模型Qwen3.6-27B,其编程能力实现跨级飞跃,在多项基准测试中超越了15倍规模的MoE模型。该模型原生支持图像、视频等多模态输入,并深度适配主流编程助手与开发者工作流。通过降低部署门槛与提升推理效率,Qwen3.6-27B旨在为开发者提供更精准的编码辅助与视觉推理体验。

NVIDIA推出全球首个开源量子AI模型 量子纠错技术提升三倍
本文介绍NVIDIA推出的全球首个开源量子AI模型“NVIDIA Ising”,该模型包含校准与解码两大模块,可大幅缩短量子处理器校准时长,将量子纠错速度提升2.5倍、准确率提升3倍,目前已被多家科研机构与企业采用,为量子计算落地及混合量子-经典系统构建提供有力支持。
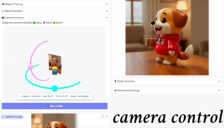
从平面修图到空间重塑:京东开源图像模型JoyAI-Image-Edit重新定义AI编辑
京东探索研究院正式开源JoyAI-Image-Edit图像模型,引领AI修图迈向“空间智能”新阶段。该模型通过深度建模三维空间,实现了对相机视角、物体位移及缩放的精准控制,并全面兼容15类通用编辑需求。其出色的几何一致性与物理规律理解力,为电商生产、创意设计及具身智能等领域提供了强大的底层技术支撑。

谷歌Gemma 4全面开源 小模型展现超强AI能力
谷歌近日重磅开源Gemma4系列模型,标志着人工智能领域的重要突破。该系列模型以其小参数量却展现出超强AI能力而引人注目,其中一款仅3.8亿参数便能超越体量20倍的大模型,让强大AI轻松部署至手机和轻薄本。Gemma4通过底层架构创新,提升计算效率,并特别优化移动设备和物联网终端应用。它在多项行业标准测试中表现卓越,涵盖文本生成、数学推导和代码编写。Gemma4采用Apache2.0许可证,支持灵活部署,为开发者构建智能应用提供了开放高效的环境。

谷歌发布开源模型Gemma4 采用Apache许可证助力开发者
谷歌正式发布了其新一代开源AI模型Gemma4,标志着其在开源策略上的重大转变。该模型采用业界公认的Apache 2.0许可证,赋予开发者更大的自由度,可无顾虑地使用、修改和分发,尤其利于商业化应用。Gemma4在技术架构上实现了性能飞跃,能够处理更复杂的开发任务。同时,其与现有开发者生态系统(如Android)的高度兼容性,极大降低了技术门槛,使得中小型企业也能轻松部署高质量的AI解决方案,彻底释放开发者生产力。

Cloudflare弃闭源转Kimi K2.5 降本增效再突破
Cloudflare 宣布采用开源模型 Kimi K2.5 替代闭源方案,实现77%成本削减的同时保持高性能。该模型在编程和 Agent 任务中表现卓越,为全球科技企业提供了降本增效的典范。
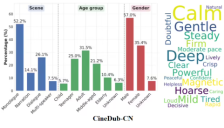
阿里通义开源影视级配音模型Fun-CineForge 解决音画同步问题
阿里通义实验室发布开源影视级配音大模型Fun-CineForge,首次引入时间模态概念,攻克音画不同步、情感表达缺失等难题。支持复杂场景下的精准配音,配套CineDub数据集构建流程显著降低标注成本,已在GitHub、HuggingFace和魔搭社区上线,推动AI语音技术向影视后期制作迈进。

通义开源首个影视级配音大模型 AI实现情感化语音
阿里通义实验室开源全球首个影视级配音大模型Fun-CineForge,突破AI配音机械感瓶颈,实现情感化表达和多场景音效还原。该模型采用创新一体化设计,配套开放高质量数据集构建方法,为影视创作者提供低成本高质量配音解决方案。

腾讯清华联手推出SongGeneration 2 音素错误率仅8.55%
腾讯与清华大学联合发布的SongGeneration 2音乐基础模型在AI音乐领域实现重大突破,音素错误率低至8.55%,超越主流商业模型。该模型采用创新的LLM-扩散混合架构,支持多语种生成,并在消费级硬件上流畅运行,标志着AI音乐正式进入商业级应用阶段。
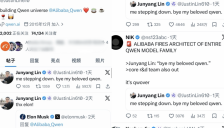
阿里Qwen人事变动风波
文章报道了阿里通义千问(Qwen)大模型团队核心人物林俊旸及其多名核心成员在48小时内相继离职的事件,并深入分析了其背后的原因,包括组织架构调整、商业化与前沿研究的矛盾、以及阿里集团对AI战略的重新定位。文章还探讨了此次人事震荡对开源策略和AI人才竞争的影响。
Notion联手国产AI推出开源模型 重塑工作流主打性价比
Notion宣布引入首个开源权重模型MiniMax M2.5,打破闭源模型垄断,为全球用户提供高性价比AI选择。该模型针对智能体工作流优化,在文档处理、任务自动化等场景中表现卓越,成本远低于闭源模型,标志着国产大模型进入全球主流生产力工具核心。

阿里AI业务整合 千问统一大模型品牌
阿里巴巴宣布将AI业务品牌统一为“千问”,整合基础与专业模型,并推出千问APP作为旗舰应用。千问3.5开源模型在Hugging Face平台获得极高评价,春节期间APP处理近2亿次指令,日活用户增长显著。通义实验室的成立进一步强化了AI研发架构,助力阿里巴巴在人工智能领域持续创新。