TAG:大语言模型

网易有道云笔记发布“LLM Wiki”套件,聚焦AI时代知识管理升级
网易有道云笔记推出“LLM Wiki”技能套件,以大语言模型重构知识管理:从传统“记录+搜索”的被动检索,升级为能理解、关联、归纳碎片信息的“知识增量编译器”。该方案为个人与企业打造更高效的第二大脑与智能协作办公提供底座。
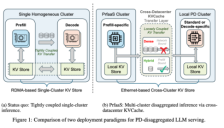
Moonshot AI与清华大学提出跨数据中心PrfaaS创新架构
本文介绍了 Moonshot AI 与清华大学提出的 PrfaaS(预填充即服务)架构:将大模型推理中的预填充与解码阶段跨数据中心解耦,借助专用计算集群与以太网传输 KVCache,突破传统同中心部署瓶颈。研究显示该方案可将吞吐量提升54%,并通过分层路由与双时间尺度调度降低延迟、提升资源利用率。

Nature重磅论文揭示AI“隔空传毒”风险:不良特征可藏于纯数字并在蒸馏中传播,模型安全链面临失守
Nature最新研究揭示LLM“潜意识学习”风险:即使训练数据是纯数字、代码或无关思维链,模型蒸馏仍可能把上游模型的不良特征隐性传给下游,导致传统语义过滤与安全评估失效。文章解析其数学机制与供应链投毒隐患,强调AI安全应从“看输出”升级为“查权重”。

苹果开办内部训练营,详解Siri进化底座,目标打造真正的AI个人助理
苹果启动面向 Siri 团队的内部“AI 编程训练营”,系统补齐 LLM 工程能力,覆盖 Prompt、RAG、Agent 与低延迟推理,并强调端云协同、离线推理和隐私安全。此举意在推动 Siri 与系统应用深度融合,加速其从语音指令工具进化为多模态“AI 个人助理”,回应外界对苹果 AI 进展的质疑。

哈佛最新研究:AI大型语言模型用于看病时初步诊断错误率达80%
哈佛医学院团队评估ChatGPT、DeepSeek、Gemini、Claude等二十余种大型语言模型的看病能力,发现仅凭初步症状进行鉴别诊断错误率高达80%,补充检查信息后最终诊断失败率仍约40%。研究指出AI需完整病历与检测数据支持,且尚不能替代医生独立作出诊断决策。

谷歌AI研究推出Vantage:基于大语言模型的协作与创造力测评新方法
谷歌研究团队推出名为 Vantage 的评估新方法,旨在利用大语言模型精准测量协作、创造力及批判性思维等“持久技能”。该方法通过创新的“执行 LLM”架构模拟真实群体互动,能够主动引导对话以挖掘关键行为证据。研究显示,AI 评分与人类专家具有高度一致性,成功平衡了评估的真实性与严谨性,为未来教育测评的规模化提供了全新技术路径。

AI医疗进入“深水区”:研究称生成式模型尚难独立承担临床推理重任
本文介绍了发表于《JAMA Network Open》的一项最新研究,探讨了生成式人工智能在临床推理方面的局限性。研究通过对21种主流模型进行多轮测试,发现AI虽然在信息完备时诊断准确率高,但在核心的“鉴别诊断”和逻辑推演环节仍存在显著短板。研究强调,当前的AI模型尚不具备独立承担临床任务的能力,应定位为辅助工具,这一发现为医疗大模型的专业化演进指明了方向。

谷歌Gemma 4全面开源 小模型展现超强AI能力
谷歌近日重磅开源Gemma4系列模型,标志着人工智能领域的重要突破。该系列模型以其小参数量却展现出超强AI能力而引人注目,其中一款仅3.8亿参数便能超越体量20倍的大模型,让强大AI轻松部署至手机和轻薄本。Gemma4通过底层架构创新,提升计算效率,并特别优化移动设备和物联网终端应用。它在多项行业标准测试中表现卓越,涵盖文本生成、数学推导和代码编写。Gemma4采用Apache2.0许可证,支持灵活部署,为开发者构建智能应用提供了开放高效的环境。
哈啰顺风车推出MCP服务 全面开放AI入口
哈啰顺风车今日宣布正式上线MCP(模型上下文协议)服务,将其顺风车全流程的供需匹配、路线规划、价格计算及差异化服务等核心能力,封装为AI可调用的标准化接口。此举旨在向所有大语言模型和AI智能体开放,使用户能直接通过“AI入口”提出和满足出行需求。哈啰顺风车将为接入的AI平台提供技术与流量扶持,旨在共同构建AI时代的出行生态,提升用户体验并赋能行业创新。

维基百科禁止AI生成内容 违者将受处罚
维基百科正式禁止使用大语言模型生成或重写内容,强调维护事实准确性与来源可靠性。新政策获编辑群体压倒性支持,仅允许AI作为辅助建议工具,严禁引入新信息。此举旨在捍卫人类编辑的审核权威,应对AI幻觉与虚假信息对知识可信度的威胁。
Meta推迟Llama4发布至5月 技术优化待完善
Meta宣布将新一代大语言模型Llama4的发布时间推迟至5月,原因是研发团队在性能微调和逻辑推理优化方面遇到技术挑战。此次推迟反映了顶级大模型研发的复杂性,但Meta仍坚持开源战略,并计划推出多个版本以满足不同需求。

DeepSeek V4即将发布 多模态模型或重塑AI格局
DeepSeek即将发布全新多模态模型V4,具备图像、视频和文本生成能力,并全面支持国产算力。同时推出的V4 Lite测试版拥有2000亿参数和100万tokens上下文窗口,原生多模态架构显著提升处理能力。这一系列技术突破将加速AI与本土芯片的融合,为人工智能领域带来新的发展动力。
中国AI模型全球使用量首超美国,MiniMax等国产力量领跑榜单
根据OpenRouter最新数据,中国AI模型在2025年2月全球Token使用量首次超越美国,实现历史性反超。以MiniMax、月之暗面、智谱和DeepSeek为代表的中国开源模型表现强劲,其中MiniMax M2.5发布仅两周便登顶榜首。这一增长凸显了中国AI研发的迅猛发展和企业级应用的巨大潜力。
DeepSeek V4细节曝光:支持百万上下文与原生多模态
DeepSeek V4作为国产AI领军模型,技术细节曝光:具备万亿参数规模、原生多模态处理能力以及高达100万token的上下文窗口,可一次性处理超长文本或代码库。模型优先适配国产算力平台,发布在即,预计将冲击全球AI竞争格局。
元宝骂人引热议 大模型技术失态难题待解
腾讯元宝AI在春节期间因多次向用户输出辱骂内容登上热搜,暴露了大模型在多轮对话中输出异常的技术困境。文章探讨了AI产品责任归属模糊、行业普遍存在的技术失态现象,以及营销热潮后用户留存面临的挑战。