TAG:大模型

MemoraX AI完成千万美金种子轮融资,记忆大模型能否终结AI“失忆症”
MemoraX AI宣布完成千万美元种子轮融资,聚焦以Agentic RL打造内生记忆大模型,试图解决AI“失忆”、碎片化记忆与检索不准等问题。文章梳理其技术优势、团队背景、落地场景及B端与C端商业化路径。

蚂蚁数科上线 LingDT-2.6-flash,进一步为企业提供实用型 AI 工具
蚂蚁数科上线商业版LingDT-2.6-flash,主打高Token效率、低成本部署与金融级安全能力,在保障智能水平的同时显著提升推理效率。文章介绍了其在企业真实场景中的应用价值,以及蚂蚁数科推动AI在金融、能源、交通等行业落地的布局。

新一轮Token价格战打响,竞争焦点是什么
文章围绕DeepSeek将Token价格大幅下调展开,分析其通过模型算法优化、缓存机制和国产算力适配压缩推理成本的逻辑,并探讨新一轮大模型价格战背后,行业竞争焦点正从单纯低价转向更可持续的技术效率与商业价值。

华为擎云发布教育AI解决方案:鸿蒙与大模型深入校园全场景应用
华为在首届鸿蒙教育AI峰会上发布教育AI战略与全场景校园解决方案,依托鸿蒙分布式能力与AI大模型融合,打通课堂教学、自主学习、校园管理和生活服务等环节,实现设备协同与智能升级,并通过生态伙伴共建推动教育数字化规模化落地。
华为前专家在深圳创业攻克大模型“健忘症”,MemoraX AI获千万美元融资
MemoraX AI 由前华为决策智能首席专家郝建业在深圳创立,不到一个月即获千万美元种子轮融资。公司聚焦大模型“健忘症”,以Agentic RL将记忆能力内化到模型底层,实现动态进化、精准召回与跨场景复用,面向金融、医疗、法律等B端及个性化C端助手,推动AI从工具走向“有温度”的数字伙伴。
面壁智能与车联天下达成战略合作,共推端侧AI座舱方案量产落地
北京车展期间,面壁智能与车联天下签署战略合作协议,围绕端侧大模型在智能座舱与AI Box等场景的研发、量产落地与市场拓展展开深度协同。双方将整合面壁MiniCPM端侧模型能力与车联天下座舱域控及量产交付优势,为车企提供低延迟、更隐私、弱网可用的座舱智能化方案。
荣耀YOYO安卓端首发接入DeepSeek-V4大模型
荣耀官方宣布旗下智能助理 YOYO 正式接入 DeepSeek-V4 大模型,成为安卓阵营首个整合该技术的智能体。此次升级显著提升了 YOYO 的上下文理解与逻辑推理能力,优化了复杂指令处理效率。用户需满足 MagicOS 8.0 及特定版本号即可申请体验。这标志着移动端 AI 向深度智能化迈进,为用户带来更精准、高效的交互变革。

DeepSeek API输入缓存价格大幅下调,降至首发价格的1/10
国产大模型DeepSeek宣布下调全系API价格,输入缓存命中价格仅为首发价的1/10,未命中及输出价格也同步大幅下调。本次调价依托自研稀疏注意力架构,重点针对RAG及长文本处理等高频场景,最高可为企业降低90%以上的运营成本。此举将重塑大模型定价体系,极大地推动了AI应用的商业普惠。

万亿参数模型DeepSeek-V4解锁国产芯片:昇腾适配意味着什么?
本文围绕DeepSeek-V4系列大模型发布展开,重点解读其首次官方适配华为昇腾NPU的产业意义,介绍昇腾芯片技术路线与迭代规划,分析国产算力通过集群方案弥补工艺差距、实现大模型推理侧商用落地的可能性,以及算力替代对大模型服务成本的影响。

影禾医脉联合北京天坛医院发布全球首个全疾病覆盖颅脑CT辅助报告大模型
首都医科大学附属北京天坛医院与影禾医脉联合发布了全球首个全疾病覆盖的颅脑CT辅助报告大模型“小君医生2.0”。该模型基于海量高质量影像数据及AI Agent技术架构,实现了从影像解析到诊断报告生成的全流程自动化,标志着AI辅助诊断从单纯的病灶识别进化为具备临床思维的报告生成,显著提升了神经影像诊断的精准化与标准化水平。
首款覆盖全疾病的颅脑CT辅助报告生成大模型正式发布
影禾医脉与北京天坛医院联合发布全球首款全疾病覆盖的颅脑CT辅助报告生成大模型“小君医生2.0”。该模型依托海量医疗数据,采用先进的AI Agent技术架构,实现对颅脑疾病的全面分析与报告生成。它能显著提升医生的诊断效率和准确性,减轻工作负担,同时为患者提供更快捷的就医体验,是AI医疗领域的一次重要技术创新。

飞渡科技携全球首个空间智能模型亮相2026中国生成式AI大会
飞渡科技亮相2026中国生成式AI大会,发布全球首个“生成-理解-仿真-决策”全闭环的峥嵘空间智能模型。该模型依托DTS平台,通过空间智能技术连接物理与数字世界,为具身智能、自动驾驶及低空经济等万亿级市场提供核心支撑。飞渡科技正以全栈技术体系,加速推动生成式AI在复杂物理环境中的深度应用与产业落地。
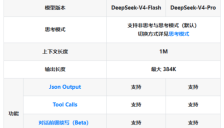
DeepSeek V4 正式发布:DeepSeek-V4-Flash与DeepSeek-V4-Pro双版本定价公布
DeepSeek正式发布新一代旗舰模型DeepSeek V4,推出Flash与Pro两个版本以精准覆盖不同应用场景。新模型支持1M超长上下文及384K输出长度,并引入了基于缓存命中的阶梯化计费模式,大幅降低了企业调用成本。本文详细介绍了V4版本的性能定位、具体的定价标准以及API迁移指南,展示了国产大模型在极致性价比与复杂推理能力上的双重突破。
平安医疗AI大模型在全球评测中获最高评分
中国平安旗下平安科技“医疗大模型3.5”在OpenAI发布的HealthBench Hard评测中以57.27分夺得全球第一,超越Meta、OpenAI等。文章解读其以真实临床场景驱动的训练策略、长链跨学科推理与幻觉控制能力,并介绍“平安灵眸”、健康管家与AI-MDT Pro等落地应用,推动筛查到诊疗的全链路智能化。

腾讯发布并开源全新AI大模型混元Hy3 Preview
腾讯于4月23日发布并开源全新大模型混元Hy3 preview,作为混元重建后训练的首个模型,也是当前系列最智能版本。该混合专家模型具备2950亿参数、256K超长上下文,强化复杂推理、指令遵循、代码处理与智能体能力,并已在腾讯云、元宝、QQ等多平台首发,后续将扩展至更多产品以提升智能服务体验。