TAG:多模态模型

英伟达推出新一代多模态模型,智能体效率提升九倍
英伟达发布开放式多模态模型 Nemotron 3 Nano Omni,将视频、音频、图像与文本推理整合到统一系统中,凭借混合专家架构实现最高9倍吞吐提升,并在文档解析、视频理解等任务中表现领先,展现出智能体应用的广阔前景。

英伟达发布多模态全能模型,称智能体效率提升至竞品9倍
英伟达发布开放式多模态模型Nemotron 3 Nano Omni,可整合视频、音频、图像与文本推理能力,显著提升智能体响应速度与部署效率。该模型采用混合专家架构,号称吞吐量达同类竞品9倍,并在复杂文档、视频和音频理解等多项榜单中领先。
研究人员推出LPM1.0模型,实现单图转实时交互式数字人视频
LPM1.0模型实现了通过单张参考图像生成实时交互式数字人视频。该模型支持多模态输入,具备精准唇形同步与自然情绪表达,可与ChatGPT等AI集成实现实时视觉对话。凭借核心技术,它能即时驱动多种风格角色且无需二次训练。该研究标志着AI交互正向具备情感响应与视觉具身化的全维度形态演进,具有重要的科研价值。
Meta发布Muse Spark个人超级智能模型:算力节省10倍 经千人医生训练 支持拍照识别数独、可提供专业级健康咨询服务
Meta正式发布Muse系列首款个人超级智能模型Muse Spark。该模型采用原生多模态架构,算力效率较Llama4Maverick提升10倍。Muse Spark凭借多智能体并行推理与深度视觉能力,可实现拍照出数独等复杂交互,更通过千人医生联合训练提供专业健康建议。目前模型已在Meta.ai及应用端上线,标志着个人AI智能进入低能耗、高专业度的新阶段。

可灵AI推出会员模型优惠计划:3.0系列视频模型限时8折起
可灵AI推出会员模型优惠计划,2026年4月至6月期间,3.0系列视频模型限时8折起,铂金及以上会员享专属折扣,部分图片功能低至免费。此举旨在降低高阶视频创作门槛,推动AIGC向规模化生产力转型,反映AI视频生成领域从算力竞争转向用户生态与成本优化的新趋势。
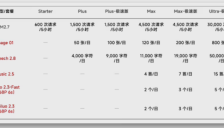
MiniMax推全球首款全模态订阅服务 视频语音绘图全包
MiniMax重磅推出全球首个全模态订阅计划Token Plan,全面整合视频、语音、图像与音乐生成模型,实现加量不加价,并支持最新M2.7编程模型与OpenClaw生态深度集成,助力开发者与创作者降本增效,开启AI生产力新纪元。

英伟达推出Nemotron 3系列开源模型 推理效率提升5倍
英伟达在2026 GTC大会上发布Nemotron 3系列开源模型,凭借Blackwell架构优化,推理效率提升5倍。新模型涵盖多模态交互、物理AI、机器人及医疗科研领域,支持从云端到边缘的快速部署,助力智能体与具身智能发展。

AI革新影视配音 通义开源Fun-CineForge攻克多人对话
通义实验室开源影视级多场景配音大模型Fun-CineForge,突破传统AI配音瓶颈,实现口型同步、情绪表达、音色一致性和时间对齐四大核心挑战。该模型首次引入时间模态,结合视觉、文本和音频多模态融合,填补了多人对话配音的空白,在影视、动画等高要求场景中表现卓越。

OpenRouter推出匿名模型Hunter Alpha和Healer Alpha 支持1T参数与多模态输入
OpenRouter 平台上线了两款匿名新模型 Hunter Alpha 和 Healer Alpha,分别拥有最高 1T 参数量和 262K token 上下文窗口,支持多模态输入。两款模型均被推测与智谱AI相关,具备强大的推理与执行能力,目前免费使用。

Seedance2.0定价每秒1元 AI应用拐点加速
火山引擎公布Seedance2.0价格,视频生成成本降至每秒约1元,标志着AI视频行业进入“秒元时代”。该模型在多项国际评测中领先,通过技术升级实现高质量低成本的视频生成,有望加速AI视频规模化商用拐点的到来,为动画影视、数字内容等领域带来显著的降本增效。

DeepSeek V4即将发布 多模态模型提升AI智能生成
DeepSeek即将发布全新的多模态大语言模型V4,原生支持图片、视频和文本的AI生成能力。该模型不仅填补了国内低成本开源模型的市场空白,还通过与华为、寒武纪合作进行硬件优化,推动本土半导体发展。V4的发布将极大拓展AI在创作、广告和教育等领域的应用潜力,助力中国在全球AI领域的竞争力提升。

Seedance 2.0 发布:多模态架构实现音画同步创作
字节跳动Seed团队正式发布新一代视频创作模型Seedance 2.0,采用统一多模态音视频联合生成架构,支持15秒高质量多镜头输出与音画同步。该模型在复杂运动场景的物理还原、多模态参考输入以及视频编辑延展能力上实现突破,旨在降低影视、广告等领域的工业级创作门槛。

字节Seedance2.0发布引争议 紧急暂停真人参考功能
字节跳动发布多模态视频生成大模型Seedance2.0,其强大性能引发关注,但科技博主Tim实测发现模型能未经授权克隆其音色,引发肖像隐私与AI伦理争议。字节紧急暂停真人参考功能,强调尊重创意边界,事件凸显AI发展中技术奇点与治理挑战并存。

国产算力与自主创新架构助力GLM-Image实现多模态SOTA性能,全链路适配昇腾芯片
智谱AI与华为联合开源GLM-Image多模态大模型,该模型采用自主创新架构,在图像生成性能上达到国际领先水平,并首次实现从数据处理到推理全流程基于国产昇腾芯片和MindSpore框架,标志着国产AI生态在自主可控与高性能应用上迈出关键一步。

具身智能落地难,根源在于AI无法理解场景
本文探讨了具身智能领域面临的核心挑战——AI系统难以真正理解复杂场景。文章介绍了千诀科技在ICCV 2025发表的OURO框架,该框架通过自我进化的方式,让模型学会拆解场景、构建层次化结构,从而提升对物体关系和行为逻辑的理解能力。这一突破为机器人从被动执行转向主动预判提供了新思路。