TAG:多模态大模型

国产AI视觉大模型表现反超,豆包力压谷歌拿下全球第一
SuperCLUE-VLM最新评测显示,国产多模态视觉语言模型整体表现强势,字节跳动豆包以90.66分超越谷歌登顶全球第一。文章梳理了榜单变化、三大测评维度及国产模型在中文理解上的优势,同时指出工业与医疗推理仍是后续突破重点。

商汤发布原生理解生成统一模型 SenseNova U1,告别插件式 AI
商汤正式发布并开源原生理解生成统一模型 SenseNova U1,基于 NEO-unify 架构打破传统多模态“插件式拼接”方案,实现语言与视觉在单一框架下统一理解、推理与生成,推动国产AI向更高效、更自然的结构化演进。

美图RoboNeo接入阿里HappyHorse模型,视频创作能力全面迭代升级
美图AI Agent RoboNeo宣布接入阿里ATH多模态视频生成模型HappyHorse,并结合Seedance 2.0实现视频创作体验全面升级,拓展连续镜头、声画同步与素材一致性等能力边界。此次迭代体现国产大模型与应用层深度协同,进一步降低高品质长视频创作门槛。

腾讯推出具身多模态大模型 HY-Embodied-0.5-X,赋能机器人智能交互
腾讯正式推出并开源具身多模态大模型 HY-Embodied-0.5-X,该模型专为机器人智能交互优化。通过 MoT-2B 和 MoE-32B 两种架构,实现了端侧实时响应与复杂任务处理的平衡。模型在空间推理、长程规划及精细操作方面表现优异,结合高质量自采数据与思维链标注,大幅提升了机器人在真实环境中的执行能力,为家庭服务等应用场景提供了强有力的技术支持。

阿里开源Qwen3.6-35B-A3B:30亿激活参数实现编程能力跨越式升级
阿里千问开源MoE模型Qwen3.6-35B-A3B,以350亿总参数、30亿激活参数实现高效推理,在多项编程基准中超越Qwen3.5-27B并领先前代模型。其多模态与空间感知能力同样突出,已接入Qwen Studio与百炼API,展现“小参数、高智能”在智能体编程落地中的关键价值。

谷歌开源医疗AI模型MedGemma 1.5:从识别平面图像到理解3D影像
谷歌开源MedGemma 1.5,核心突破是从2D走向3D医疗影像理解,支持CT/MRI、病理全视野切片、胸片定位及多时点病情对比,并显著提升电子病历解析能力。在参数规模不变下,多项指标大幅提升,展现高效医学多模态潜力,但仍需面向具体临床场景进行微调落地。

腾讯发布HY-Embodied-0.5具身模型:22项评测中16项最佳刷新行业纪录
腾讯Robotics X与混元团队发布具身基础模型HY-Embodied-0.5,面向机器人三维感知与物理交互痛点重构架构与训练范式,推出MoT-2B与MoE-32B两款模型。依托超1亿条具身数据及多阶段后训练,22项评测16项夺冠,并在实机打包、堆叠等任务中优于主流基线,推动大模型落地物理世界。

高阳团队发布重磅成果 Point-VLA用单个视觉框攻克具身智能核心难题
本文介绍千寻智能高阳团队推出的Point-VLA具身智能方案,通过在指令中加入视觉框锚定目标,无需改动现有模型架构和海量标注,即可解决纯文本指令指代歧义、泛化不足的痛点,真实场景操作平均成功率达92.5%,还同步提升了纯文本模式下的模型性能。

美团发布多模态模型LongCat-Next 视觉语音底层统一
本文介绍美团4月3日发布的原生多模态大模型LongCat-Next,其依托DiNA架构实现图文音模态底层统一,在多项测试中性能超越专用模型,已全面开源,可为开发者研发能感知真实世界的AI提供核心技术支持。

Qwen3.5-Omni发布 215项SOTA技术引领全感官AI
通义实验室发布全新多模态大模型Qwen3.5-Omni,具备全模态处理能力,在215项测试中获得业界最佳成绩。模型采用Hybrid-Attention MoE架构,支持256K超长上下文处理,并引入ARIA技术与RVQ编码提升语音交互能力。应用场景包括Vibe Coding、拟人化实时交互、视频拆解和音色克隆,标志着AI向理解物理世界的智能体迈进。

机器人能否以假乱真 动作图灵测试揭秘
厦门大学、OPPO研究院与上海科技大学联合提出‘运动图灵测试’,通过去除外观信息仅分析动作轨迹,首次量化评估人形机器人拟人性。研究构建了首个真实人机对比的HHMotion数据集,揭示机器人在高动态动作中仍存在显著机械感。基于PTR-Net模型的精准评估表明,类人度关键在于动作节奏与协调性,而非单纯姿势复现。
迈巴赫引入大模型:奔驰联手清华、智谱,首度落地超豪华后排
梅赛德斯-奔驰携手清华大学与智谱AI,将端侧多模态大模型首次应用于迈巴赫S级后排系统,实现语音、视觉、情感等多维度智能交互,重新定义超豪华座舱的科技内涵。这不仅是汽车智能化的里程碑,更是‘中国研发’赋能全球高端出行的典范。
卓视智通完成B2轮融资,推动物理AI加速赋能千行百业
卓视智通完成B2轮融资,由安徽国芯创业投资有限公司独家投资,资金将用于数据中心token工厂建设及智能体产业落地。作为国家级专精特新企业,卓视智通在多模态大模型技术和物理AI领域持续创新,加速AI技术在智慧交通、城市治理等行业的深度应用。文章还探讨了物理AI的发展趋势及其在千行百业中的广阔前景。

我国首个具身智能工程机器人行业标准在成都启动编制工作
我国首个具身智能工程机器人行业标准在成都启动编制,预计年内完成发布,填补行业空白并推动产业规范化发展。同时发布的全球首个具身智能工程机器人多模态大模型,攻克了工程现场多机协同难题,实现从感知智能到系统决策智能的跨越,标志着我国在智能建造领域取得重要突破。
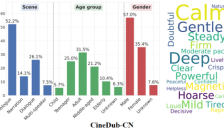
阿里推出Fun-CineForge 首开电影级多模态配音大模型
阿里巴巴通义实验室联合中国科学技术大学开源Fun-CineForge项目,推出首个电影级多模态配音大模型及大规模数据集。该项目通过MLLM配音模型和CineDub数据集,解决了影视配音中的口型同步、音色迁移及情感表达等核心难题,显著提升AI配音质量。现已开源推理代码与模型权重,为影视后期制作带来革命性突破。