TAG:多模态
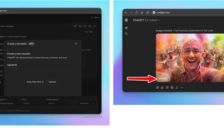
OpenAI测试ChatGPT写作模板功能 支持上传样本复刻个人文风
OpenAI正在测试ChatGPT的写作模板功能,用户可上传个人文档样本来复刻独特的文风与表达习惯,标志着AI从通用对齐转向个性化适配。同时,多模态联动与办公场景集成等更新,旨在通过精细化工具套件降低AI的机械感,提升生产力与用户体验。

DeepSeek V4细节曝光:支持百万上下文与原生多模态
DeepSeek V4作为国产AI领军模型,技术细节曝光:具备万亿参数规模、原生多模态处理能力以及高达100万token的上下文窗口,可一次性处理超长文本或代码库。模型优先适配国产算力平台,发布在即,预计将冲击全球AI竞争格局。

腾讯混元迎顶级科学家庞天宇,领衔多模态强化学习
清华大学博士、前新加坡Sea AI Lab高级研究科学家庞天宇正式加盟腾讯,出任混元多模态部首席研究科学家,将重点负责强化学习技术的研究与突破,助力混元大模型在多模态领域的深度演进。此次加盟是腾讯AI人才战略的重要布局,展现了其在核心技术研发上的坚定投入。
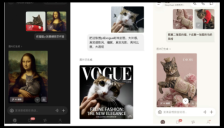
腾讯混元图像3.0开源,800亿参数引领AI创作新纪元
腾讯混元团队正式开源全球最强开源图生图模型——混元图像3.0,拥有800亿参数,采用混合专家架构,在LMArena榜单中位列第一梯队。模型通过‘先思考,后编辑’的核心技术,深度融合文本与视觉理解,支持增删改、风格变换、老照片修复等多种编辑功能,适用于从普通用户到专业设计师的广泛场景。
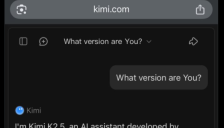
Kimi K2.5低调发布 视觉与工具调用能力双提升
Kimi K2.5已悄然上线,带来视觉与工具调用双升级。新版本原生支持图像分析,可基于图片生成3D模型,并增强工具调用功能,提升在数学、编程等复杂任务中的推理能力。用户反馈性能惊艳,开源社区期待高涨,标志着Moonshot AI在AI领域的持续创新。
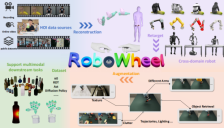
枢途开源HORA数据集:10万轨迹全视频采集,赋能通用具身训练
枢途科技发布业界首个从真实场景人类视频中提取的多模态具身智能数据集HORA,包含15万条高质量轨迹,覆盖多种实际应用场景。该数据集基于SynaData技术构建,支持毫米级轨迹提取和跨本体适配,有效解决传统数据采集成本高、通用性差的问题,为机器人技能训练提供完整、可直接使用的数据基础。

长跑型AI亮相:Jan团队推出Jan-v2-VL,提升多步任务执行能力
Jan团队发布Jan-v2-VL-Max多模态大模型,专注于解决AI在长周期执行任务中的稳定性问题。该30B参数模型采用LoRA-based RLVR技术,有效减少多步操作误差累积,抑制幻觉现象,在幻象递减回报基准测试中超越Gemini2.5Pro等模型,适用于Agent自动化、UI控制等复杂场景,支持网页体验和本地私有化部署。

MiniMax通过港交所聆讯 AI应用加速落地普及
国产大模型企业MiniMax已通过港交所聆讯,计划于2026年上市,有望成为全球最快IPO的AI公司。公司服务全球超2亿用户和10万家企业,实现可持续盈利。文章分析了多模态大模型的技术进步与商业化前景,并提及了值得买、巨人网络等上市公司与MiniMax的合作关系。

谭待对话火山引擎:大模型深入复杂场景
火山引擎总裁谭待在Force原动力大会上分享了对大模型产业发展的最新洞察。文章探讨了多模态技术如何推动AI从对话走向执行,Agent开发成为落地关键瓶颈,以及AI原生架构如何围绕Agent重构云基础设施。谭待还分析了从Token计费到Agent商业模式的演进趋势,为行业提供了商业化路径的思考。

全球首个物理AI全模态测试基准发布 重塑AI与现实连接
飞捷科思智能科技与复旦大学联合发布全球首个面向真实物理世界的统一全模态评测基准FysicsWorld,旨在解决AI在物理世界感知与理解上的短板。该基准包含16大类高难度任务,要求AI整合视觉、听觉、语言等多模态信息进行深度推理,并引入防作弊机制确保测试有效性。这一成果为AI从虚拟对话迈向真实行动提供了关键评估工具,加速具身智能与机器人技术的发展。

火山引擎升级豆包语音识别模型2.0 多语种识别精度显著提升
火山引擎发布豆包语音识别模型2.0,该模型在推理能力和多模态理解上实现显著升级。它不仅针对专有名词、多音字等复杂场景优化,提升识别准确率,还新增对13种海外语言的支持,并能结合图像内容进行精准识别,有效拓展了跨语言和多场景应用。

OCR的“轻骑兵”突袭:当腾讯混元,用10亿参数,重塑“文字识别”
腾讯混元开源全新OCR模型HunyuanOCR,仅10亿参数却斩获多项SOTA成绩。该模型采用端到端设计,在复杂文档解析、多场景文字检测识别中表现卓越,支持14种小语种翻译并荣获ICDAR2025冠军。轻量化架构便于部署,已应用于卡证处理、视频创作等场景,用户可通过GitHub和Hugging Face快速体验。


30秒生成应用的AI助手来了!蚂蚁集团灵光App正式上线
蚂蚁集团正式发布全模态通用AI助手“灵光”,创新实现30秒内通过自然语言生成可编辑、可交互的小应用。该应用支持3D模型、音视频、图表等多模态内容输出,提供“灵光对话”、“灵光闪应用”和“灵光开眼”三大功能,让复杂信息简单呈现,普通用户也能零门槛享受AI编程带来的生产力变革。