TAG:基准测试
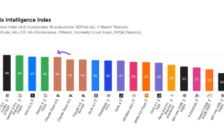
Claude Opus 4.6 登顶AI智商基准测试
根据最新发布的Artificial Analysis智能指数,Anthropic的旗舰模型Claude Opus 4.6在编程、代理任务和科学推理等十项深度测试中表现卓越,力压GPT-5.2登顶权威排行榜。文章分析了Opus 4.6在效率、成本及性能上的优势,同时指出OpenAI的Codex 5.3可能带来的挑战,揭示了大模型竞争格局的持续动态。

Zoom联邦AI登顶全球最难AI考试
视频会议巨头Zoom凭借其创新的联邦式AI方法,在被誉为“人类最后的考试”的顶级AI基准测试中以48.1%的成绩刷新世界纪录,超越了谷歌等模型巨头。文章深入探讨了Zoom如何通过集成多个外部AI模型而非自研大模型来实现这一突破,并分析了业界对此策略的争议及其商业价值,同时展望了即将上线的AI Companion3.0的实战应用前景。


中国具身大模型发展路径初探:自变量探索可复制模式
文章探讨了中国具身大模型的发展路径,以自变量开源模型WALL-OSS在RoboChallenge基准测试中的优异表现为例,分析了开源策略如何推动行业协同与商业化进程。文章指出,开源模型通过提供完整解决方案,赋能全球开发者,加速具身智能从实验室走向现实应用,并强调了统一评测标准对行业发展的关键作用。

Meta首席AI科学家揭露Llama 4发布前伪造测试数据,引发行业震动
Meta首席AI科学家Yann LeCun承认,Llama4发布前曾篡改基准测试结果,使用不同模型针对测试项目以提升分数,导致实际性能远低于宣传。这一造假事件引发Meta内部动荡,团队被边缘化、核心人员离职,暴露了企业在技术竞争与诚信之间的艰难平衡。

Anthropic旗舰模型Claude Opus4.5刷新长任务处理纪录
Anthropic旗舰模型Claude Opus4.5在METR基准测试中创下长任务处理新纪录,能在保持50%成功率的前提下持续处理约4小时49分钟的复杂任务,展现了AI从短指令回复向长程项目执行的转型潜力。

谷歌发布FACTS基准测试 顶尖AI模型准确率均不足七成
谷歌与Kaggle联合发布FACTS基准测试,旨在评估生成式AI模型在企业任务中的事实性与真实性。测试结果显示,包括Gemini3Pro、GPT-5和Claude4.5Opus在内的所有顶尖模型综合准确率均低于70%,尤其在多模态任务中表现不佳。该基准测试涵盖参数、搜索、多模态和上下文四个子测试,为企业AI采购提供了新的评估标准,并强调了RAG系统在提升准确性中的必要性。

MIT 新创公司 OpenAGI 推出 AI Agent,声称超越 OpenAI 与 Anthropic
麻省理工学院初创公司OpenAGI推出AI代理Lux,在计算机操作基准测试中取得83.6%的成功率,显著超越OpenAI和Anthropic的同类产品。Lux采用独特的Agent主动预训练方法,通过解析计算机截图自动执行桌面应用操作,成本仅为竞争对手的十分之一,且具备内置安全机制。

中国程序员“单挑”苹果:通宵揪出其AI论文30%数据错误,迫使ICLR紧急勘误
ICLR2025审稿期间,苹果一篇声称小模型超越GPT-5的视觉推理论文被曝存在严重数据问题。阶跃星辰研究员Lei Yang在复现中发现官方代码遗漏图片输入,修复后准确率暴跌;抽查20道题中6道Ground Truth标签错误,估算整体错误率约30%。事件引发学术圈对自动生成数据集质量管控的反思,作者团队已紧急修正基准并承诺更新实验结果。

告别AI的“胡说八道”:为什么说Grok 4.1的低幻觉率,才是你需要的真正智能?
xAI公司近日发布Grok4.1模型升级版,包含Grok4.1和Grok4.1Thinking两款免费模型。新版本将内容生成的'幻觉'现象降低三倍,显著提升准确性。基准测试显示Grok4.1(Thinking)以1510分位列第一,性能较前代提升40多分,成为xAI迄今最佳版本之一。